Om Labs Tops ScreenSpot-Pro
Keon Kim and Krish Chelikavada

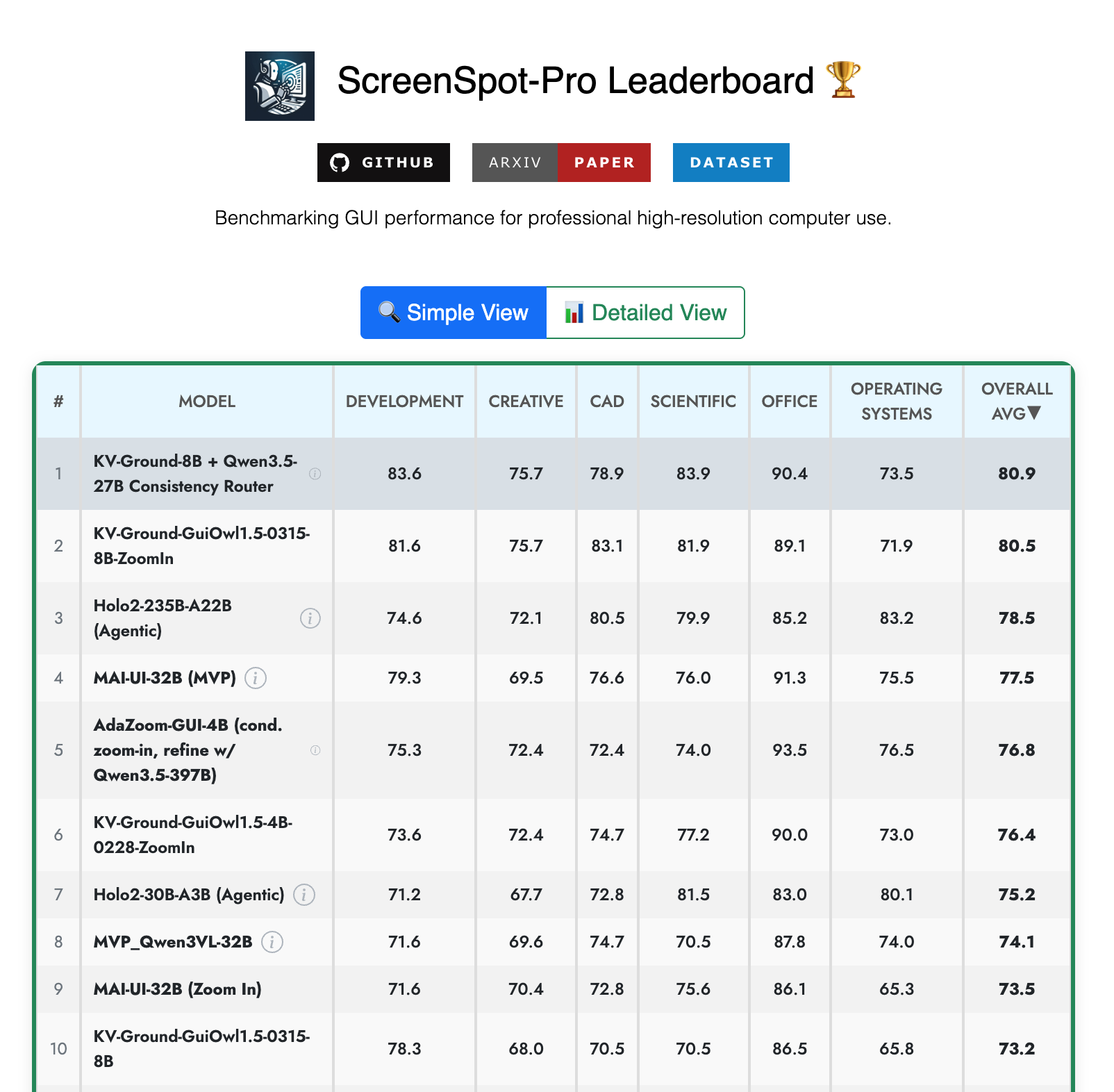
We published a new research paper, Zoom Consistency, and it currently holds the #1 spot on the ScreenSpot-Pro Leaderboard, the main benchmark for measuring how well AI can use professional software.
| Method | Accuracy |
|---|---|
| Zoom Consistency Router (ours) | 80.9% |
| KV-Ground-8B + ZoomIn (prev. #1) | 80.5% |
| Holo2-235B (H Company) | 78.5% |
| MAI-UI-32B (Alibaba) | 77.5% |
| AdaZoom-GUI (Lenovo + Tsinghua) | 76.8% |
What is ScreenSpot-Pro?
Imagine asking an AI to click the right button in Photoshop, find a menu item in Excel, or navigate AutoCAD. ScreenSpot-Pro tests exactly that: given a screenshot of real software and an instruction like "click the Bold button," can the AI find and click the right spot?
The benchmark was created by researchers at the National University of Singapore and published at ACM Multimedia 2025, one of the top academic conferences in the field. It covers 1,581 tasks across 29 professional applications spanning Windows, macOS, and Linux. The leaderboard is actively contested by teams from Alibaba (#4), H Company (#3, ex-DeepMind), Lenovo + Tsinghua University (#5), and Zhejiang University + Ant Group (#8), among others.
What we found
Today's best AI systems use a two-step process to click on screens. First, the AI looks at the whole screen and makes a rough guess where to click. Then it zooms into that area and makes a more precise guess.
Everyone throws away the rough guess after zooming in. We noticed it's actually useful.
If the AI's zoomed-in guess lands right in the center of the zoomed view, it means the first guess was already good. If the zoomed-in guess is way off-center, something probably went wrong early on.
We call this signal zoom consistency, defined as the distance between the zoomed-in prediction and the crop center:
c = ||p̂₂ − m||₂
where p̂₂ is the step-2 prediction and m = (500, 500) is the center of the cropped view. We proved that under idealized conditions (the target is in the crop and step 2 is accurate), this simplifies to:
c = ||ε₁|| / r
where ε₁ is the step-1 error and r is the crop ratio. Zoom consistency is a direct, linear readout of how far off the first guess was. With a typical crop ratio of 0.5, the zoom magnifies step-1 error by 2x: a consistency value of 100 corresponds to a step-1 error of just 50 pixels.
This signal requires no extra computation, no training data, and no access to model internals. Because it's a geometric quantity in a shared coordinate space, it's directly comparable across different models without calibration. Log-probabilities can't do this because they depend on each model's tokenizer, vocabulary, and temperature.
Here's the full method:
def zoom_pipeline(model, image, instruction, r=0.5):
p1 = model(image, instruction) # step 1: full image
crop = crop_and_resize(image, center=p1, ratio=r)
p2 = model(crop, instruction) # step 2: zoomed crop
c = distance(p2, (500, 500)) # zoom consistency
final = remap(p2, crop_box)
return final, c
def route(image, instruction):
pred_A, c_A = zoom_pipeline(specialist, image, instruction)
pred_B, c_B = zoom_pipeline(generalist, image, instruction)
return pred_A if c_A <= c_B else pred_BThe consistency c (line 5) is extracted from the pipeline's existing intermediate output. No additional forward passes are needed beyond the zoom pipelines themselves.
In practice, the signal works. Across 1,581 ScreenSpot-Pro samples, zoom consistency correlates significantly with prediction correctness (p < 10⁻⁶). Samples where the AI was most consistent (c < 30) had 87.1% accuracy, compared to 75.6% for the least consistent samples (c ≥ 250).
How we used it
We ran two AI models on every task: a specialist and a generalist. For each task, we checked which model had lower zoom consistency (meaning higher confidence) and picked that model's answer.
Think of two experts looking at the same problem. You pick whichever one seems more sure. The "sureness" signal was free all along.
Why this matters
Most software in the world was built for humans. ERPs, medical records systems, government portals, legacy CRMs: they have no APIs, no integrations, no way to automate them except through the screen. GUI agents change that. An AI that can see a screen and click the right buttons can automate any software, regardless of whether it was designed for automation. That's why every major AI lab (Anthropic, Google, OpenAI, Microsoft) is investing in this space.
The core challenge is confidence. Today's GUI agents click with the same conviction whether they're right or wrong. In a demo, that's fine. In production, where an agent is submitting forms, executing trades, or modifying patient records, that's dangerous.
Zoom consistency gives agents a way to measure their own confidence on every click, using information they already have. Agents can ask for help before clicking something irreversible, combine multiple models by picking the most confident answer, and detect when something has changed (like a UI update) before it causes errors.
For GUI agents to move from demos to production, they need self-awareness about their own limitations. Zoom consistency is a step toward that, and it was hiding in plain sight.
Setup and reproducibility
We ran all experiments on a single NVIDIA H200 (141GB) with two models running simultaneously: KV-Ground-8B (a GUI grounding specialist) and Qwen3.5-27B (a general-purpose VLM). The zoom consistency router adds zero inference cost since it's computed from values the pipeline already produces.
We used the standard ScreenSpot-Pro evaluation with no modifications to the benchmark, no task-specific prompting, and no ensembling beyond the consistency router.
All code, model weights, and reproduction instructions are available at github.com/omxyz/zoom-consistency-routing.
Read more
Citation
Please cite this work as:
Kim, Keon and Chelikavada, Krish, "Om Labs Tops ScreenSpot-Pro", Om Labs, Apr 2026.
Or use the BibTeX citation:
@article{kim2026omlabstopsscreenspotpro,
author = {Keon Kim and Krish Chelikavada},
title = {Om Labs Tops ScreenSpot-Pro},
journal = {Om Labs},
year = {2026},
note = {https://omlabs.xyz/blog/zoom-consistency-tops-screenspot-pro},
}